
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- NLP
- RNN
- 파워BI
- 신입일기
- pl300
- 구글애널리틱스
- microsoft pl-300
- 길벗출판사
- gru
- data
- ga4
- 오블완
- 태블로
- 인턴일기
- 티스토리챌린지
- pl-300
- 데이터분석
- 태블로기초
- 모두의구글애널리틱스4
- GA4챌린지
- PowerBI
- 파워비아이
- LSTM
- microsoft power bi
- POWER BI
- 태블로입문
- Today
- Total
수영장의 수영_데이터 분석 블로그
[NLP] 10. BERT(Bidirectional Encoder Representations from Transformers) 본문
[NLP] 10. BERT(Bidirectional Encoder Representations from Transformers)
슈빔멘 2022. 1. 21. 21:42BERT
트랜스포머 기반의 pre-trained 언어 모델 중 하나이다
버트의 핵심은 비지도학습 기반의 대규모 사전 훈련(Pre-training)에 있다. 꼭 버트가 아니더라도 언어 모델은 사전훈련이 적용된 모델이 대세라고 한다. (GPT도 사전 훈련 언어모델에 해당한다) 버트 이전의 사전훈련 언어모델을 먼저 알아본다.
사전 훈련 언어 모델
BERT이전에도 사전 훈련된 모델을 활용한 언어모델이 꽤나 있었다. 수업시간에 배운 모델은 'ELMo'이다
ELMo (Embeddings from Language Model)
- 새로운 워드 임베딩 방법론으로, '언어 모델로 수행하는 임베딩' 이런 해석이 될 듯 하다. 사전훈련된 언어모델을 사용한다.
- Word2Vec, GloVe 임베딩 방법론은 '문맥'에 따라 단어 의미가 달라질 수 있음에도, 문맥에 따라 다르게 워드 임베딩을 하지 못했다는 한계가 있었다- ELMo는 문맥을 고려한 워드 임베딩(Contextualized Word Embedding)이라는 차별점을 두었다. 문맥을 어떻게 고려하느냐? 바로 '양방향 언어 모델' (biLM)으로 수행한다
biLM (Bidirectional Language Model)
- 기본적인 RNN은 문장의 앞부터 뒤쪽으로 hidden state가 업데이트 되어간다ex) I know him. I met Jisu before.- 대충 이런 문장이 있다치면, 인간은 him이 곧 'Jisu'라는 남자를 지칭함을 안다. 언어는 앞에서 뒤로만 흐르는 게 아니기 때문이다. 하지만 기존의 RNN(순방향 RNN)이라면 .. 모를 것이다
- 이런 문제에 착안하여 양방향 언어 모델 (Bidirectional Language Model)은 역방향으로도 hidden state를 업데이트한다
- ELMo는 양방향 LSTM을 사용한다

- 'play' 시점에 있다고 하자.
Forward 모델 내부에는 2 개의 hidden layer가 있고, play는 임베딩 벡터를 거친 출력 벡터와 은닉층 두개를 지나며 출력 벡터 두 개를 반환한다. 총 3개의 출력 벡터를 얻었다
- Backward 모델도 마찬가지로 총 3개의 출력 벡터가 반환된다
- 이제 총 6개의 출력 벡터를 연산한다
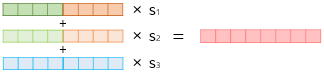
1) 각 층의 출력값을 concat (임베딩 - 은닉층1 - 은닉층2)
2) 각 층별로 가중치를 할당한다 (s1, s2, s3)
3) 각 층의 출력값을 모두 더한다
=> ELMo로 워드 임베딩 완성 ^^

- E : 기존 워드 임베딩 레이어
- T : 엘모를 거친 최종적인 워드 임베딩
BERT(Bidirectional Encoder Representations from Transformers)
특징
- 트랜스포머를 기반으로 한다
- 그 중에서도 '인코더'만을 쌓아올린 구조이다
- Label이 없는 방대한 텍스트 데이터로 pre-trained 되었다 (약 33억 단어)
- 사전훈련 모델은 Label이 있는 데이터로 추가훈련을 하면서, 실제 task에 맞게 파라미터를 재조정해 성능을 높여간다. 이 추가훈련 과정을 파인 튜닝 fine-tuning이라 한다.
크기

- BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
- BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
- L : layer 개수, Encoder를 몇 개 쌓아올릴 것인지에 해당한다
- D : 입/출력의 dimension -> 트랜스포머에서의 입력을 생각해보면 [행(시퀀스 길이) 열(dmodel)]이다. D는 트랜스포머의 dmodel에 해당한다
- A : 셀프 어텐션의 헤드 개수
이제 BERT 구조를 하나씩 상세히 살펴보자
BERT의 입력 이해하기
1. 문맥을 반영한 임베딩 (Contextual Embedding)

그림은 BERT가 각 입력 단어를 임베딩하는 구조를 보여주고 있다.
- BERT에 입력되는 모든 단어는 이미 임베딩 레이어를 거친 임베딩 벡터이다. BERT는 이 임베딩 벡터을 한 번 더 '임베딩'하는데, '문맥 정보를 고려한' 임베딩을 하게 된다. BERT내에서 하나의 단어는 모든 단어를 참고한 연산을 거쳐 최종적인 출력 임베딩벡터로 반환된다
- 여기서 문맥을 반영한 출력 임베딩을 얻는 방법은 '셀프 어텐션Self-Attention'

-> BERT는 트랜스포머의 인코더 부분을 12번(24번) 쌓아올린 것이므로 각 레이어 내부는 두 가지 서브층(멀티 헤드 셀프어텐션, 피드포워드 신경망)으로 구성된다. 여기서 셀프어텐션을 거쳐 Contextual Embedding을 하게 되는 것이다
2. 서브워드 토크나이저 WordPiece
- BERT는 입력 문장을 단어보다는 더 작고, 캐릭터보다는 더 큰 '서브워드' 단위로 토큰화한다.
- 사용하는 토크나이저는 WordPiece로 바이트 페어 인코딩(Byte Pair Encoding, BPE) 알고리즘과 유사하다
- 기본 아이디어
자주 등장하는 단어는 그대로 Vocabulary에 추가한다
자주 등장하지 않는 단어는 서브워드 단위로 분리해 추가한다
- OOV 문제 해결
어떤 단어가 입력으로 들어왔을 때, Vocabulary에 해당단어가 없다면?
-> 일반 토크나이저 : unknown을 반환한다 (OOV 문제 발생)
-> 서브워드 토크나이저 : 입력 단어를 서브워드로 쪼갠 후에 Vocabulary에 해당 서브워드가 있는지 매치한다
ex) 'embeddings' -> em, ##bed, ##ding, #s
3. 포지션 임베딩 (Position Embedding)

- 포지션 임베딩은 단어의 위치정보를 표현하는 임베딩으로, 트랜스포머의 포지셔널 인코딩과 유사하나 sin cos함수가 아닌 '학습'을 통해 위치 정보를 얻는다
1) 문장 길이만큼의 포지션 임베딩 벡터를 만든다 (그림 : 0 1 2 3)
2) 각 포지션 임베딩 벡터를 학습시킨다
3) 단어 임베딩벡터(파란색)에 학습된 포지션 임베딩벡터(회색)를 더해준다
4. 세그먼트 임베딩 (Segment Embedding)

- 트랜스포머와 달리 버트에서는 '세그먼트 임베딩' 층이 추가된다
- '문장 레벨의 위치 임베딩'으로 생각할 수 있겠다
- 첫번째 문장의 단어들은 0, 두번째 문장의 단어들은 1, ...
-> 결론적으로 버트의 입력에는 총 3개의 임베딩 레이어가 들어간다
- WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
- Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
- Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
BERT의 Pre-training 구조 이해하기
사전 훈련을 위해 어떤 방법을 쓸까? 두 가지 방법으로 나뉘는데, Masked Language Model(MLM)과, Next Sentence Prediction(NSP)가 있다
1. 마스크드 언어 모델 (Masked Language Model, MLM)
- 트랜스포머의 디코더에서는 현재시점 이후의 단어 벡터를 마스킹했다. 그 이유는 예측할 단어(미래시점 단어)를 치팅하는 것을 방지하기 위함이었다. 버트에서도 이 '마스킹' 방법을 활용하는데, 트랜스포머의 마스킹과는 당연히 좀 다르다
- BERT는 입력 텍스트의 15% 단어를 마스킹한다. 이 때 랜덤으로 골라진 15% 단어를 다시 세 종류로 나눈다.
- 80%의 단어들은 [MASK]로 가린다
- 10%의 단어들은 랜덤한 단어로 변경한다
- 10%의 단어들은 그대로 둔다
정리하자면,
- 전체 단어의 85%는 마스크드 언어 모델의 학습에 사용되지 않음
- 학습에 사용되는 12%는 [MASK]로 변경 후에 원래 단어를 예측
- 1.5%는 랜덤으로 단어가 변경된 후에 원래 단어를 예측
- 1.5%는 단어가 그대로지만, 모델은 이 단어의 변경 유뮤를 알 수 없음

- 원래 문장 : 'my dog is cute / he likes playing'
- 마스킹 : dog -> [MASK]
- 변경 : he -> king
- 유지 : play -> play
- MLM Classifier는 각 빨간 단어들을 예측하는 task를 수행하며, pre-training한다
2. 다음 문장 예측 (Next Sentence Prediction, NSP)
- MLM이 단어를 예측하는 훈련이라면, NSP는 문장이 서로 연결되는지를 맞추는 훈련이다
- Sentence A, Sentence B를 입력으로 넣는데, 50:50 확률로 실제로 이어지는 문장이거나, 이어지지 않는 문장이 들어간다


- [CLS] : Classification embedding, NSP를 수행하는 위치 토큰.
NSP Classifier가 여기서 두 문장의 연결유무 이진분류를 수행한다 - [SEP] : Packed Sentence Embedding, 문장을 구분하는 토큰. 문장 끝
BERT 파인 튜닝(Fine-tuning) 이해하기
MLM과 NSP로 사전학습을 마쳤다면, 그 뒤에 내가 풀고자 하는 task에 대한 데이터를 추가로 학습시키며 파인 튜닝한다
특징적으로는 자연어와 관련한 여러가지 task를 다양하게 적용할 수 있다
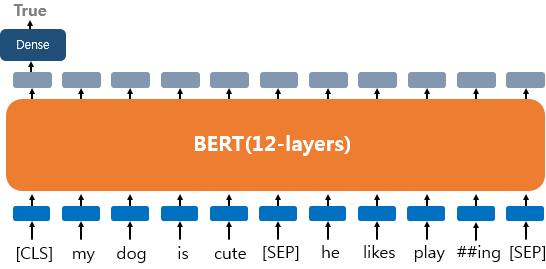
1) Single Text Classification 하나의 텍스트에 대한 텍스트 분류

- 입력된 문서에 대해 분류를 하는 유형 -> ex) 영화 리뷰 감성분석, 뉴스 카테고리 분류 등
- [CLS] 토큰 위치의 출력층에서 밀집층(Dense)을 추가하여 분류에 대한 예측을 수행한다
(Dense layer = fully-connecte layer)
2) Tagging 태깅 작업

- 각 단어에 대한 품사 태깅
- 개체를 태깅하는 개체명 태깅
-> [CLS], [SEP] 토큰을 제외하고, 각 단어 위치의 출력층에 Dense layer를 달아 태깅을 진행한다
3) Text Pair Classification or Regression 텍스트 쌍에 대한 분류 및 회귀
자연어 추론 (Natural Language Inference)
: 두 문장이 주어졌을 때, 하나의 문장이 다른 문장과 논리적으로 어떤 관계가 있는지 분류하는 기법
-> 모순 관계(contradiction), 함의 관계(entailment), 중립 관계(neutral) 등이 있다
- NSP처럼 텍스트 사이에 [SEP]토큰을 넣어 문장을 구분해준다
4) Question Answering 질의 응답

- 입력 : 본문(context)과 질문(question)으로 이루어진 텍스트 쌍
ex) SQuAD(Stanford Question Answering Dataset) 데이터셋이 유명하다
- 질문과 본문을 입력받으면, 본문에서 정답을 추출(extract)해서 출력으로 반환한다
- Machine Reading Comprehension (MRC)라고도 불린다

그 외 BERT에 관한 것
모델 설정
- Train Data : 위키피디아 25억 단어 + BooksCorpus 8억 단어
- 최대 입력의 길이는 512이다 (Sentence A + Sentence B)
- 100만 step을 훈련했다 (33억 단어에 대해 40 epoch을 학습했다)
- Optimizer : Adam
- Learning Rate : 10^-4
- Weight Decay : L2 Normalization, 0.01
- Drop Out : 모든 Layer 0.1 dropout 적용
- Activation Function : GeLU
- Batch Size : 256
어텐션 마스크 (Attention Mask)
- BERT 내부에서 어텐션 연산이 수행될 때, 실제단어가 아닌 패딩토큰에 대해서는 어텐션되지 않도록 조치를 취하는 것을 어텐션 마스크라한다

- 맨 아래에 1과 0으로 이루어진 시퀀스가 추가로 입력되었다
- 1 : 해당 토큰은 실제 단어이다 -> 마스킹 X
- 0 : 해당 토큰은 패딩 토큰이다 -> 마스킹

마지막으로 BERT 한 장 정리 ~
1.2.3을 막힘없이 설명할 수 있는가? -> YES
버트 공부 잘 됐군
'Goorm 자연어처리 전문가 양성 과정 2기 > NLP' 카테고리의 다른 글
| [NLP] 11. Tokenization (0) | 2022.01.25 |
|---|---|
| [NLP] 09. Transformer 트랜스포머 (0) | 2022.01.19 |
| [NLP] 07. Attention Mechanism (0) | 2022.01.16 |
| [NLP] 08. Preprocessing(전처리) (0) | 2022.01.12 |
| [NLP] 06. LSTM & GRU (0) | 2022.01.11 |



