
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- NLP
- pl-300
- 티스토리챌린지
- RNN
- ga4
- 길벗출판사
- pl300
- GA4챌린지
- 오블완
- 파워비아이
- 구글애널리틱스
- POWER BI
- 신입일기
- data
- microsoft pl-300
- 파워BI
- PowerBI
- 모두의구글애널리틱스4
- 태블로입문
- 태블로기초
- gru
- 태블로
- 데이터분석
- 인턴일기
- LSTM
- microsoft power bi
- Today
- Total
수영장의 수영_데이터 분석 블로그
[NLP] 09. Transformer 트랜스포머 본문
쓰
트랜스포머는 정말 ~ 어렵다
나만 이렇게 어려운걸까?
정리하면서 명확히 이해되지 않는 부분을 체크해보자
참고 : https://wikidocs.net/31379
1) 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인
wikidocs.net
Transformer 기본 아이디어
- RNN을 사용하지 않는다
- 그러나 seq2seq 처럼 인코더-디코더로 구성되어 있다
- 이 때 인코더와 디코더는 N개(복수)로 구성된다


하이퍼 파라미터
dmodel = 512
트랜스포머의 인코더, 디코더는 입력과 출력의 크기가 항상 유지된다는 특징이 있음. dmodel은 그 크기(차원)를 의미한다
문장 행렬이 input 될 때 (seq_len, dmodel)의 크기를 가지며, 출력될 때도 마찬가지다 => 행: 문장 길이, 렬 : dmodel
num_layers = 6
인코더, 디코더를 몇 개 쌓을지 정하는 하이퍼파라미터. 6이면 인코더 6, 디코더 6개씩이다
num_heads = 8
멀티-헤드 어텐션이라는 어텐션 방식을 활용하는데, 어텐션을 여럿으로 분할해 병렬적으로 수행하는 방식이다. num_heads는 이 병렬 수를 의미한다
dff = 2048
FFNN(피드포워드 신경망)의 hidden state 크기를 의미한다.

1. Encoder - Input 이해하기
- RNN처럼 단어를 순차적으로 입력받지 않는다
- 입력 문장 전체를 한 번에 입력받는다
- 시퀀스의 '위치 정보'를 위해 Positional Encoding을 추가한다
Positional Encoding


- 임베딩을 거친 입력 문장은 하나의 행렬로 (입력 시퀀스 길이 * 임베딩 사이즈dmodel) 크기를 갖는다
- 여기에 포지셔널 인코딩 행렬을 더한다
- dmodel : 인코더, 디코더에서의 입력, 출력 차원 크기. 하이퍼 파라미터이며 이 차원은 입력 ~ 인코더 ~ 디코더 ~ 출력가지 계속 유지된다.
- pos : 입력 문장에서의 임베딩 벡터 위치 ex) 'am'의 경우 두번째 행이므로 2
- i : 임베딩 벡터 내 차원 인덱스
=> 이 때 차원 인덱스 i 값이 홀수냐 짝수냐에 따라 포지셔널 인코딩 값을 다르게 계산한다
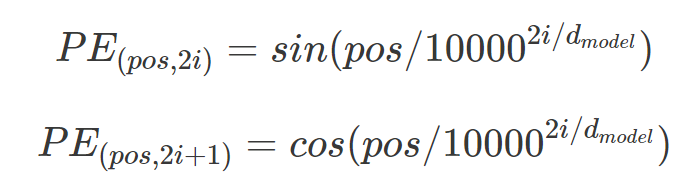
=> i가 짝수일 경우 sin함수를, 홀수일 경우 cos함수를 사용한다
결과적으로, (input 문장 임베딩 행렬 + 포지셔널 인코딩 행렬)이 Encoder에 입력된다
2. Encoder 층 이해하기

딱 봐도 세 가지 층이 보임 -> 서브층1 'Multi-Head Attention', 서브층2 'Feed Forward', 끼인(?) 층'Add&Norm'
1) 첫번째 서브층 - Multi-head Self-Attention 멀티헤드 셀프어텐션
- 셀프 어텐션이란 무엇인가?
기본 어텐션은 디코더의 hidden state가 쿼리, 인코더의 hidde state가 키, 밸류가 된다
셀프 어텐션의 경우 Q,K,V가 모두 같은 경로(인코더면 인코더, 디코더면 디코더)에 있다는 차이가 있다
Q: 입력 문장의 모든 단어 벡터들
K: 입력 문장의 모든 단어 벡터들
V: 입력 문장의 모든 단어 벡터들

예를 들어 'The animal didn't cross the street because it was too tired.'라는 문장에서 'it'과 유사도가 가장 높은 단어를 찾고자 한다. 쿼리는 'it'이 되고, 입력 문장 내 모든 단어들과의 유사도를 구해(Attention Score), 분포와 컨텍스트 벡터를 얻는다.
인코더 층의 멀티-헤드 셀프 어텐션의 연산 과정은 다음과 같다
(1) 쿼리, 키, 값 벡터
위의 Encoder 내부 구조를 자세히 보면 멀티 헤드 어텐션의 입력에는 세 가지 화살표가 들어가 있다. 각각 Q,K,V에 해당하며, 세 가지 모두 입력 문장에서 얻어낸다.
- 여기서 각 벡터는 dmodel 차원보다 작은 차원으로 뽑아진다
- 각 벡터의 차원은 dk = dmodel / num_heads로 결정된다

- student 벡터 : 1 x dmodel
- 가중치 벡터 : dmodel x (dmodel/num_heads)
- Q, K, V : 1 x (dmodel/num_heads)
(2) Scaled dot-product Attention
- 기존 어텐션 : 각 Q와 모든 K에 대해 어텐션 스코어를 구하고 - 분포 구하고 - Value를 구한다
- 스케일드 닷-프로적트 어텐션 : 어텐션 스코어를 구할 때 단순히 Q와 K를 dot product 한 뒤 루트 n으로 나눠준다

- 여기서 $d_k$는 dmodel/num_heads에 해당한다
- 트랜스포머 논문에서는 d_k = 64 이므로 8로 나누어준 값이 Attention Score가 된다

-> 이후로는 기존 어텐션의 연산과정과 같이 Attention Distribution, Attention Value를 구해주면 된다
=> 최종 값을 단어 'I'에 대한 어텐션 값(=Context Vector)라 부르게 된다
(3) 행렬 연산으로 한 번에 Attention 연산하기

-> 각 단어에 대한 Q,K,V를 구하는 것이 아니라, 행렬의 형태로 문장 입력 전체에 대해 쿼리, 키, 벡터를 구해준다

-> 그리고 어텐션 스코어, 분포, 값을 각각 계산해준다
-> 수식으로 나타내면 다음과 같다

그러나 여기서 끝이 아니다
이렇게 생긴 Attention을 동시다발적(병렬적)으로 여러 번 수행하는게 바로 멀티 헤드 어텐션이다
(4) 멀티 헤드 어텐션 Multi-head Attention

- 각각의 차이를 머리 속에 잘 새겨넣어야한다
1) 입력 단어(토큰) 차원에서의 어텐션
2) 입력 문장, 즉 행렬 차원에서의 어텐션
3) 입력 문장, 여러 개의 W로 연산되는 어텐션'들' -> num_heads 값만큼의 어텐션을 수행한다
- 논문에서는 8개의 병렬 어텐션이 이루어진다
- 어텐션 헤드 : 각각의 어텐션 값 행렬 ( a0, a1, ... a num_heads )
이렇게 어텐션을 병렬적으로 수행하는 이유는 무엇일까?
=> 다양한 시각으로 정보를 수집하기 때문에 모델의 효율성이 높아진다


1. 병렬 어텐션 수행
2. 모든 어텐션 헤드를 concat
3. 가중치 행렬 Wo를 곱함
-> Multi-head Attention의 최종 결과 matrix가 도출된다
-> 이 때 매트릭스의 크기는 입력 문장 행렬 크기와 같다 ()
2) 두번째 서브층 - Position-wise FFNN 포지션-와이즈 피드포워드 신경망
기본적인 fully-connected layer라고 볼 수 있다.

- x : multi-head attention의 결과 matrix => (
- W1 : ()
- W2 : (dmodel)
(dff는 하이퍼 파라미터, 논문에서는 2048로 지정)

- 특징 : 인코더 내의 서브층을 거치는 와중에도 행렬의 크기는 (seq_len, dmodel)을 계속 유지한다
- 중요!! <- 당연함 덧셈 연산을 위해서는 행렬 크기가 같아야함
3) 잔차 연결(Residual Connection)과 층 정규화(Layer Normalization)


(1) 잔차 연결 Add
'서브층의 입력과 출력을 더하는 것'을 잔차 연결이라 한다
모델의 학습을 돕는 기법이라 한다
(2) 층 정규화 Norm
서브층을 거쳐서 - 잔차 연결 하고 - 그리고 '마지막 차원에 평균과 분산을 구해 정규화 하는 것'을 층 정규화라 한다
정규화 과정
- 평균과 분산을 활용해 정규화하기
- 정규화된 값에 감마와 베타를 도입하기

층 정규화를 위해 화살표 방향으로 각각의 평균, 분산을 구한다.
각 x를 Xi로 표기하면 층 정규화는 이렇게 쓸 수 있다

이 식에 감마와 베타를 도입해 최종 정규화 수식을 완성할 수 있다


3. 인코더에서 디코더로 넘어가기
인코더의 내부 구조를 뜯어봤고, 두 개의 서브층으로 구성(+add&norm)되어 있음을 알 수 있었다.
트랜스포머에선 이 인코더를 한 번만 거치는 것이 아니라, 'num_layer' 개수만큼의 인코더를 거친 후 디코더로 넘겨준다

-> num_layers만큼 인코더를 거친 후의 출력을 디코더에게 전달한다
-> 빨간 화살표가 디코더 층으로 2개 들어가는데 무엇이 전달되냐?
=> Key, Value이다
4. Decoder - Input 이해하기

-> 인코더랑 동일하게, 입력 단어들의 임베딩 층 + 포지셔널 인코딩을 거친 문장행렬이 input 된다
-> 현재 트랜스포머의 task는 영어 문장을 프랑스어로 변환하는 것이었다
-> 문제가 생겼다 => '<sos> je suis étudiant'는 번역할 문장, 즉 output값에 해당한다는 점이다
ex) 'suis'를 예측하는 시점에서 모델에게 주어져야하는 것
- 인코더 층에서 열심히 서브층 돌려서 만들어낸 Key, Value (모든 input 단어에 대해)
- 디코더 층에서는 'suis' 전까지 등장한 프랑스단어에 대한 임베딩행렬 (즉, '<sos> je'까지만)
=> 그러나 이미 디코더는 전체 문장 행렬을 한꺼번에 입력받았다
=> 해결 : 룩-어헤드 마스크(look-ahead mask)를 첫번째 서브층에서 실행한다
5. Decoder 층 이해하기
1) 첫번째 서브층 - Masked Multi-head Self-Attention 마스크드 멀티-헤드 셀프-어텐션
첫번째 서브층에서는 룩-어헤드 마스크가 적용된 셀프 어텐션을 수행한다
룩-어헤드 마스크 : 디코더의 현재 시점보다 미래에 있는 단어는 참고하지 못하도록 Attention Score 매트릭스의 값을 0으로 마스킹하는 것

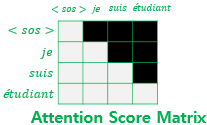
그냥 어텐션이라면 좌측처럼 그냥 쿼리와 키를 곱해서 Attention Score Matrix를 도출하지만, 디코더에서는 현재 시점보다 뒤의 단어는 '모델이 예측하고자 하는 정답 값'이므로 마스킹하는 것이다
-> 이 후로 어텐션 분포와, 어텐션 값을 구하는 방식은 인코더의 어텐션과 정확히 동일하다
2) 두번째 서브층 - Encoder-Decoder Attention 인코더-디코더 어텐션

- Key와 Value는 인코더가 마지막으로 뱉어낸 output 행렬로부터 얻는다
- Query는 디코더의 현재 시점 단어에 해당하고, 첫번째 서브층에서 나온 output 행렬로부터 얻는다

-> Key는 인코더로부터 왔기 때문에 - 'I am a student' 영어이다
-> Query는 디코더로부터 왔기 때문에 - '<sos> je suis etudiant' 프랑스어이다
3) 세번째 서브층 - Position-wise FFNN
인코더 층의 연산과 정확히 동일하다
(Add&Norm - 잔차연결과 층 정규화 또한 동일하다)
-> 마지막으로 Dense, softmax 함수를 거쳐서 출력값을 뱉어내게 된다
-> 소프트맥스를 거쳤으니 output은 Attention Distribution처럼 총합이 1이 되는 확률값이 적힌 매트릭스가 될 것이다
ex) 지금 시점이 t=1이고, 다음 단어 'suis'를 예측해야한다고 가정해보자
<sos> je suis etuidant
-> 각 단어 토큰 <sos> / je / suis / etuidant에 대해 각각 확률값을 반환한다
-> 이 확률 값은 그 단어가 다음 시점(t=2)의 단어가 될 확률을 의미한다
어렵드앙..~~
이미 수업은 BERT랑 GPT까지 나갔다
열심히 공부해서 주말까지 BERT, GPT도 정리끝내야지
떼읭,,
'Goorm 자연어처리 전문가 양성 과정 2기 > NLP' 카테고리의 다른 글
| [NLP] 11. Tokenization (0) | 2022.01.25 |
|---|---|
| [NLP] 10. BERT(Bidirectional Encoder Representations from Transformers) (0) | 2022.01.21 |
| [NLP] 07. Attention Mechanism (0) | 2022.01.16 |
| [NLP] 08. Preprocessing(전처리) (0) | 2022.01.12 |
| [NLP] 06. LSTM & GRU (0) | 2022.01.11 |



