
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- pl-300
- 태블로입문
- gru
- LSTM
- microsoft pl-300
- 오블완
- 태블로기초
- 태블로
- 인턴일기
- 신입일기
- data
- PowerBI
- POWER BI
- 파워BI
- 길벗출판사
- ga4
- 데이터분석
- microsoft power bi
- 구글애널리틱스
- RNN
- pl300
- 파워비아이
- 티스토리챌린지
- 모두의구글애널리틱스4
- NLP
- GA4챌린지
- Today
- Total
수영장의 수영_데이터 분석 블로그
[NLP] 07. Attention Mechanism 본문
seq2seq
인코더 - 디코더로 이루어져 있는 모델로, 앞서 배운 RNN에 기반한 모델로 볼 수 있음
1. 입력 시퀀스를 인코더가 받는다
2. 인코더를 거쳐 컨텍스트 벡터라는 고정된 크기의 벡터로 압축한다
3. 디코더를 거쳐 컨텍스트 벡터를 출력 시퀀스로 반환한다
-> 컨텍스트 벡터는 하나의 고정된 벡터기 때문에 모든 정보를 압축하기 어렵다
-> 기울기 소실 문제에서 자유롭지 못하다
=> 곧 어텐션의 기본 아이디어가 됨
Attention 기본 아이디어
- 어텐션은 쿼리(Query), 키(Key), 값(Value) 세 가지로 구성된다
- 디코더에서 출력 단어를 예측하는 매 time step마다, 인코더의 전체 입력문장을 다시 참고한다
- 특히 전체 입력문장 중에서도, 출력할 단어와 연관성이 높은 단어를 더욱 집중해서 참고한다

Attention(Q, K, V) = Attention Value
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
-> 예를 들어, t 시점에서는 'I am' 다음에 올 단어 'student'를 예측해 출력해야한다고 가정하자
-> 어텐션의 종류는 다양하지만 가장 기본적인 닷-프로덕트 어텐션을 공부해보겠음
- 닷-프로덕트 어텐션
1) Attention Score 계산하기

어텐션 스코어 : 디코더 내 현재 시점 t에서 단어를 예측하기 위해, 인코더의 모든 hidden state 각각과 디코더의 현 hidden state의 유사도를 판단하는 스코어
- 디코더 은닉 상태 : St
- 인코더 은닉 상태 : h1 ~ hn
=> 인코더의 각 시점 별 은닉 상태를 디코더의 은닉상태와 dot product 해준다
=> 어텐션 스코어 모음 값을 et에 저장한다

2) Attention Distribution 계산하기

어텐션 분포 : 어텐션 스코어에 소프트맥스 함수를 적용시킨 확률 분포
-> e^t에 소프트맥수를 걸어 0~1 사이값이 되는 확률 분포를 얻어낸다
-> 이 때 각 값의 총 합은 1이된다
-> 각 값은 어텐션 가중치(Attention Weight)라고 부른다

3) Attention Value 계산하기
어텐션 값 : 지금까지 계산한 어텐션의 최종 결과로, 인코더의 문맥(정보)를 담고 있다 하여 Context Vector로도 불린다
Weighted Sum (가중합)
-> 각 인코더 hidden state (h1 ~ hn)와 어텐션 가중치 값들을 곱한다
-> 곱한 값들을 모두 더한다
=> 이 값이 Attention Value가 된다

4) Attention Value와 디코더의 은닉 상태(t)를 연결하기
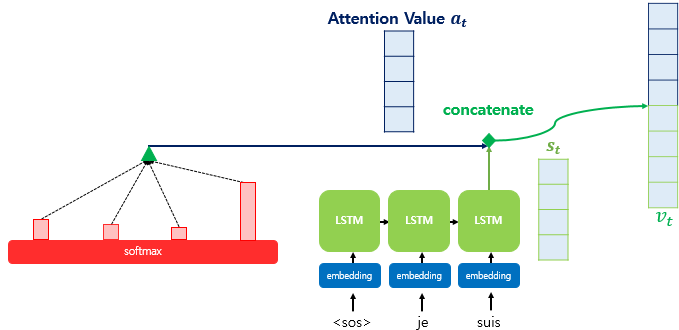
- 어텐션 값을 통해 인코더의 input 문장 중 어떤 부분을 집중(attention)할 지 알 수 있게 되었다
- 이제 이 어텐션 값은 쿼리에 해당하는 디코더의 hidden state와 연결해준다 (concatenate)
=> 이렇게 반환된 Vt는 디코더에서 그 다음 단어를 예측하는 task의 입력 값으로 사용된다
=> 이 때 바로 Vt를 출력층에 입력하는 것이 아니라, 신경망 연산을 한 번 거쳐서 input한다


=> 가중치 행렬과 Vt를 곱한 뒤 tanh 함수를 씌운다
=> 최종 출력층 input st~을 반환하게 된다
가중치 행렬 Wc의 크기 : (hidden state 크기, hidden state 크기 * 2)
Vt의 크기 : (hidden state 크기 * 2, 1)
5) 예측 벡터를 출력해내기

=> 최종적으로 소프트맥스 함수에 가중치/편향을 걸어주면 예측 벡터가 출력된다
Attention 종류

깍 많다
트랜스포머 모델에서 scaled dot Attention이 사용되고, 바다나우 (concat) 어텐션도 종종 봤다
나머지는,, 나중에 필요하면 공부해야지 머
'Goorm 자연어처리 전문가 양성 과정 2기 > NLP' 카테고리의 다른 글
| [NLP] 10. BERT(Bidirectional Encoder Representations from Transformers) (0) | 2022.01.21 |
|---|---|
| [NLP] 09. Transformer 트랜스포머 (0) | 2022.01.19 |
| [NLP] 08. Preprocessing(전처리) (0) | 2022.01.12 |
| [NLP] 06. LSTM & GRU (0) | 2022.01.11 |
| [NLP] 05. RNN (0) | 2022.01.07 |



