
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- pl-300
- gru
- PowerBI
- 태블로
- 티스토리챌린지
- microsoft pl-300
- pl300
- 데이터분석
- 파워BI
- GA4챌린지
- 태블로입문
- 길벗출판사
- POWER BI
- RNN
- 신입일기
- ga4
- data
- LSTM
- 파워비아이
- 인턴일기
- 오블완
- microsoft power bi
- 모두의구글애널리틱스4
- NLP
- 구글애널리틱스
- 태블로기초
- Today
- Total
수영장의 수영_데이터 분석 블로그
[NLP] 04. Word Embedding - Word2Vec, GloVe, Doc2Vec 본문
[NLP] 04. Word Embedding - Word2Vec, GloVe, Doc2Vec
슈빔멘 2022. 1. 6. 10:21워드 임베딩이란?
- 한 마디로 단어를 벡터로 표현하는 것
(문자를 컴퓨터가 이해가능한 형태로 변환하는 것)
=> 단어 간 의미적 유사성을 벡터화 하는 작업
왜 벡터화를 하냐?
- '유사한' 단어는 짧은 거리를, 그렇지 않으면 먼 거리를 가지게 된다
- 즉, 공간 상에 단어를 찍어낸다 == 거리(유사도)의 측정이 가능해진다는 의미이다
- 유사한 단어, 의미 분류가 용이해짐
Word2Vec 워드투벡터
- one-hot vector : 단어벡터 간 유사도 측정이 불가능하다, 사실상 단어에 인덱스만 붙인 것이기 때문
- Word2Vec : 단어의 의미를 수치화할 수 있는 벡터
분산 표현(distributed representation)
- 가정 : 비슷한 문맥에서 등장하는 단어는 비슷한 의미를 갖는다
- low dimension상에 단어의 의미를 '분산시켜' 표현하는 방식
- '벡터의 차원 == 단어집합 크기'인 원-핫 벡터와 달리, 저차원으로 나타낼 수 있다는 장점이 있다
Window
- 중심 단어 기준 앞, 뒤 몇 개의 단어를 볼 지 결정하는 범위
- 범위를 정해서 이 window를 좌우로 움직여가며 학습 데이터셋을 구축한다 => sliding window
학습 방식 1. CBOW(Continuous Bag of Words)
주변에 있는 단어(context word)로 중앙 단어(center word)를 예측하는 방식
학습 방식 2. Skip-Gram
중앙 단어로 주변에 있는 단어를 예측하는 방식
학습 알고리즘

1. Input layer의 dim과 output layer의 dim은 같다 = vocab 개수
2. hidden layer의 dimension은 지정할 수 있다
3. W1, W2
4. 마지막엔 softmax 함수를 거쳐 각 원소 값을 0~1, 총합 1로 변환한다
(다중 클래스 분류를 위하여)
5. 실제값과 예측값에 대한 오차를 구해 줄여나가는 방식
ex) I study math
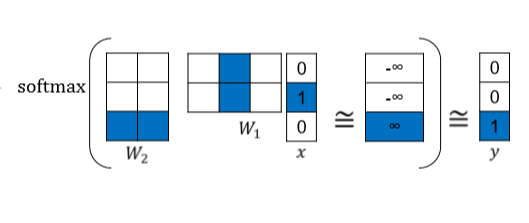
- Input : 두 번째 워드, 즉 study
- output : 세 번째 워드, 즉 math
=> 이 word2vec 구조는 해당 문장에서 study를 입력해 -> math를 출력하도록 하는 구조이다
활용

- 왼쪽의 파란 벡터는 모두 '성별차이'(남성-여성)를 표현하는 벡터임
- 즉, 각각 다른 단어들로부터 같은 '특성'을 표현하는 벡터를 찾을 수 있다
- 종합적으로 의미론적 유사도를 측정하는데 다방면으로 활용된다
GloVe (Global Vectors for Word Representation)
- 워드투벡터의 단점은 한 눈에 알 수 있는데, 바로 window로 묶인 구조라는 점
( 주변 단어만을 고려하기 때문에, doc 전체의 정보를 반영하지 못한다 )
=> 이러한 문제를 해결할 수 있는 방법론으로 GloVe가 있다
=> GloVe의 핵심은 'Co-occurrence'라는 개념에 있다
Co-occurence Matrix 동시 등장 행렬
- 행과 열을 전체 단어 집합의 단어들로 구성하고, i 단어의 윈도우 크기(Window Size) 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬
ex)- I like deep learning- l like NLP- I enjoy flying
위 세 문장의 데이터를 window size = 1 으로 임베딩한다고 하자
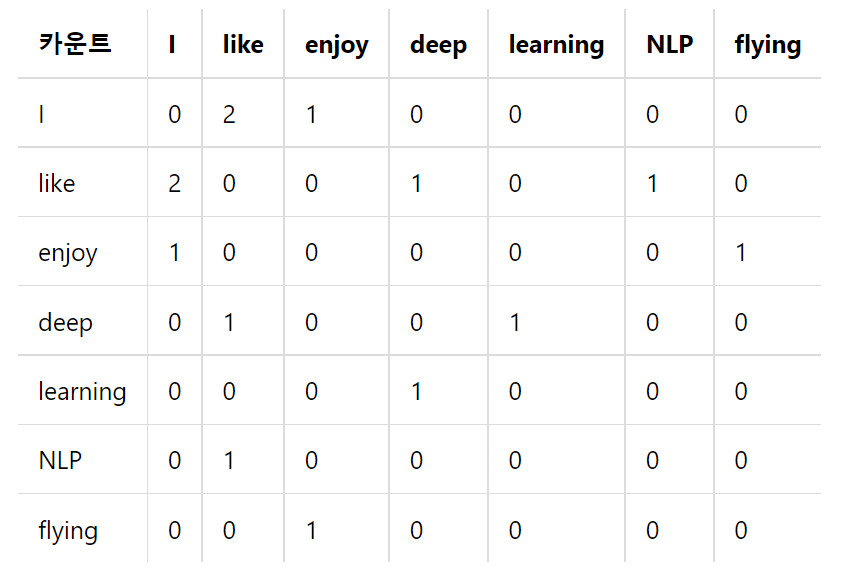
- 특징으로는 대각위치에는 당연히 0이 들어간다는 것- 전치해도 동일한 행렬이 된다는 것=> 이 co-occurence 행렬을 기반으로 계산을 이어가게 된다
Loss Function
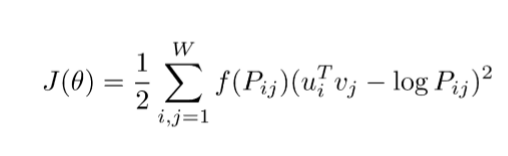
- Pij
P(j|i), 중심단어 i가 등장했을 때 윈도우 사이즈 내에서 주변단어 j가 등장하는 확률
ex) P(today|live), 단어 live가 등장했을 때, today가 등장할 확률
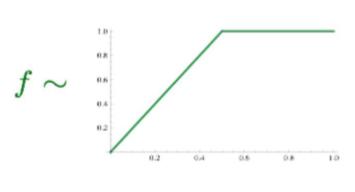
- f(P)
가중치 함수, 단어 등장 횟수에 비례하게 가중치를 곱해준다
(특정 빈도를 넘어서면 가중치 값이 일정하다)
- u, v
중심단어(i)와 주변단어(j)의 임베딩 벡터
=> 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것
Doc2Vec
- 워드투벡터의 확장으로 텍스트 데이터 뿐만 아니라, 메타 정보까지 포함해 임베딩한다
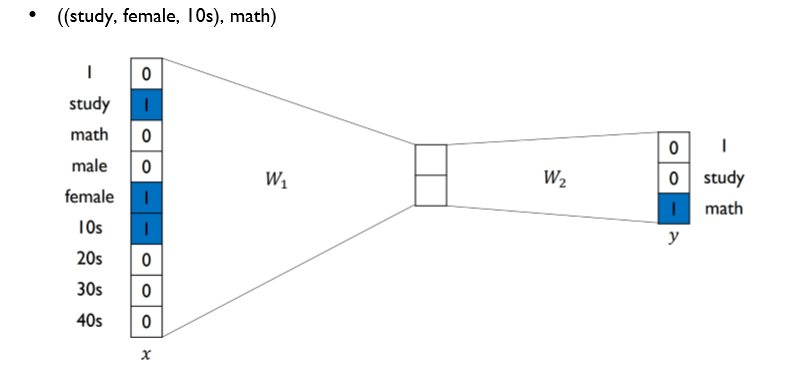
- math 라는 단어를 예측하기 위해 (study, female, 10s) 세 가지 데이터가 input된다

- word2vec과 거의 유사하나 x에 1로 들어가는 행이 여러(multi)개이다
- 이때 total loss는 세 loss의 합으로 계산한다 (word의 loss + gender의 loss + age의 loss)
- 워드투벡터와 거의 같고, W1와 x의 연산 시에 1인 데이터가 여러개라는 차이만 있다
'Goorm 자연어처리 전문가 양성 과정 2기 > NLP' 카테고리의 다른 글
| [NLP] 06. LSTM & GRU (0) | 2022.01.11 |
|---|---|
| [NLP] 05. RNN (0) | 2022.01.07 |
| [NLP] 03. Topic Modeling (0) | 2022.01.05 |
| [NLP] 02. Word Embedding, Naïve Bayes Classifier (0) | 2022.01.03 |
| [NLP] 01. Intro (0) | 2022.01.03 |



