
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 오블완
- NLP
- pl-300
- data
- 데이터분석
- 신입일기
- microsoft pl-300
- RNN
- pl300
- 파워BI
- POWER BI
- GA4챌린지
- ga4
- 태블로입문
- microsoft power bi
- 티스토리챌린지
- gru
- PowerBI
- 태블로
- 인턴일기
- 구글애널리틱스
- 모두의구글애널리틱스4
- 길벗출판사
- 태블로기초
- LSTM
- 파워비아이
Archives
- Today
- Total
수영장의 수영_데이터 분석 블로그
[NLP] 02. Word Embedding, Naïve Bayes Classifier 본문
워드 임베딩이란 무엇인가?
간단하게 인간의 언어(문자)를 컴퓨터가 이해할 수 있는 언어(숫자, 데이터, 벡터)로 변환하는 과정
- 어찌보면 당연하게도 임베딩을 어떻게 하느냐에 따라 성능이 크게 달라진다
- 현재는 인공신경망을 활용해 학습시킨 워드 임베딩 방식으로 문자를 -> 수치화하게 되었다
워드 임베딩의 종류(구분)

1) Bag of Words 가정 : 텍스트의 의미는 단어 사용의 '빈도수'에 의해 드러난다
2) 언어 모델 : 단어의 등장 '순서'를 고려해 단어 시퀀스의 자연스러움에 확률을 부여한다
3) 분포 가정 : 단어 의미는 주변의 문맥을 통해 유추할 수 있다
여기서 오늘은 백오브워즈를 자세히 배웠음
Bag of Words 가정
- 문법, 순서 등을 고려하지 않은 채 단어의 '빈도수'로 중요도를 카운트하는 방식
- one-hot 벡터로 인코딩하고 그냥 횟수를 세면 된다
Naïve Bayes Classifier

- 베이즈 정리에 기초한 분류 방식
- 클래스 별로 토큰을 count하는 간단한 방식으로 볼 수 있다

- P(d | c)로부터 P(c | d)를 계산
- 즉, 기존 스팸/정상 메일에서 사용된 토큰(단어)의 횟수를 세서 -> Test 메일의 스팸 여부를 분류한다


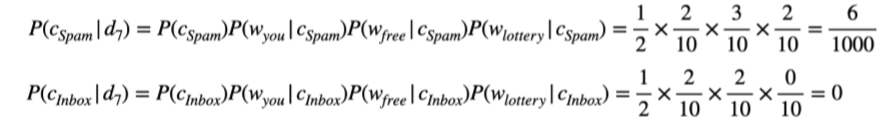
대충 이렇게 된다
수업 끝났으니까 빨리 밥먹으러 가야겠음
'Goorm 자연어처리 전문가 양성 과정 2기 > NLP' 카테고리의 다른 글
| [NLP] 06. LSTM & GRU (0) | 2022.01.11 |
|---|---|
| [NLP] 05. RNN (0) | 2022.01.07 |
| [NLP] 04. Word Embedding - Word2Vec, GloVe, Doc2Vec (0) | 2022.01.06 |
| [NLP] 03. Topic Modeling (0) | 2022.01.05 |
| [NLP] 01. Intro (0) | 2022.01.03 |
'Goorm 자연어처리 전문가 양성 과정 2기/NLP' Related Articles
more


