자격증/빅데이터분석기사
[빅분기 실기] 하루에 끝내는 작업형 1유형 - 기본 속성
슈빔멘
2021. 11. 28. 20:59
걍 기본적인 것들
Data Set 코로나 백신
https://www.kaggle.com/moonssong/1-covid-vaccination
작업형1 예상문제 - covid vaccination
Explore and run machine learning code with Kaggle Notebooks | Using data from COVID vaccination vs. mortality
www.kaggle.com
1. 데이터 셋 보기
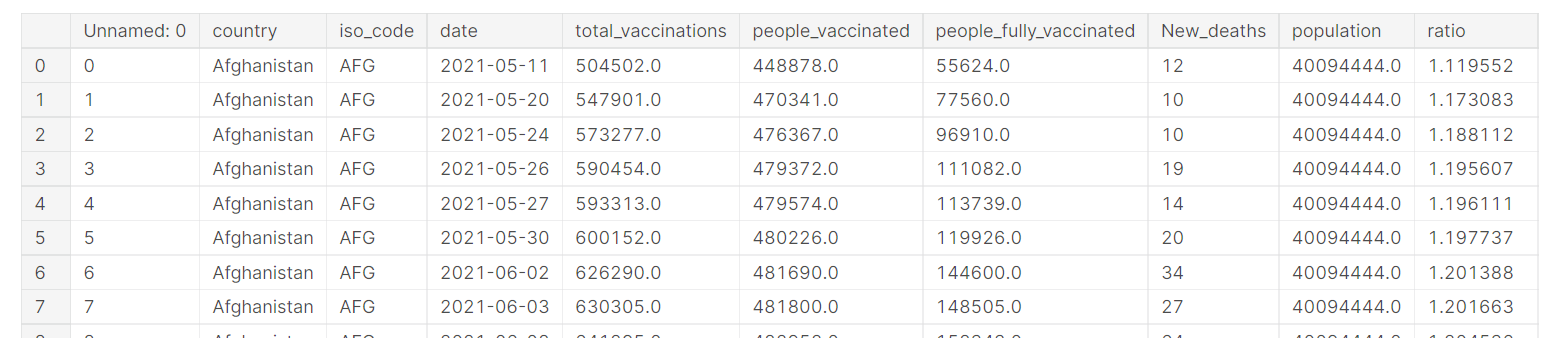
문자/숫자 데이터가 골고루 있다
1열의 경우 의미없는 열이므로 drop 해줘야겠다
날짜도 있네...
시계열 분석도 나오면 난 뒤졋다 1도할줄모르는대,,,
최대/최소값
df = pd.read_csv('data/corona.csv')
df['ratio'].min() # ratio 최소값
df['ratio'].max() # ratio 최대값그룹화
# 각 국가별로 ratio 열의 최소/최대값 출력
df[['ratio']].groupby(df['country']).min()
df[['ratio']].groupby(df['country']).max()정렬(내림차순/오름차순)
# 내림차순
df = df.sort_values(by = 'ratio', ascending = False)
# 오름차순
df = df.sort_values(by = 'ratio', ascending = True)평균, 표준편차, 표준화
mean = df.ratio.mean()
std = df.ratio.std()
scale = (df.ratio-mean)/std
-----------------------------
mean = df['ratio'].mean()
# 이런 식으로 써도 똑같음 [['ratio']]던가??올림/내림
컬럼 추가/삭제
df['새로운열이름'] = df['ratio'] + df['ratio']
# ratio 값을 두 번 더한 데이터 열을 추가함
df.drop
문자열 분할
a = 'hi bimo'
b = a.split(' ')
# 스페이스를 기준으로 문자열 가르기
# b = ['hi', 'bimo']